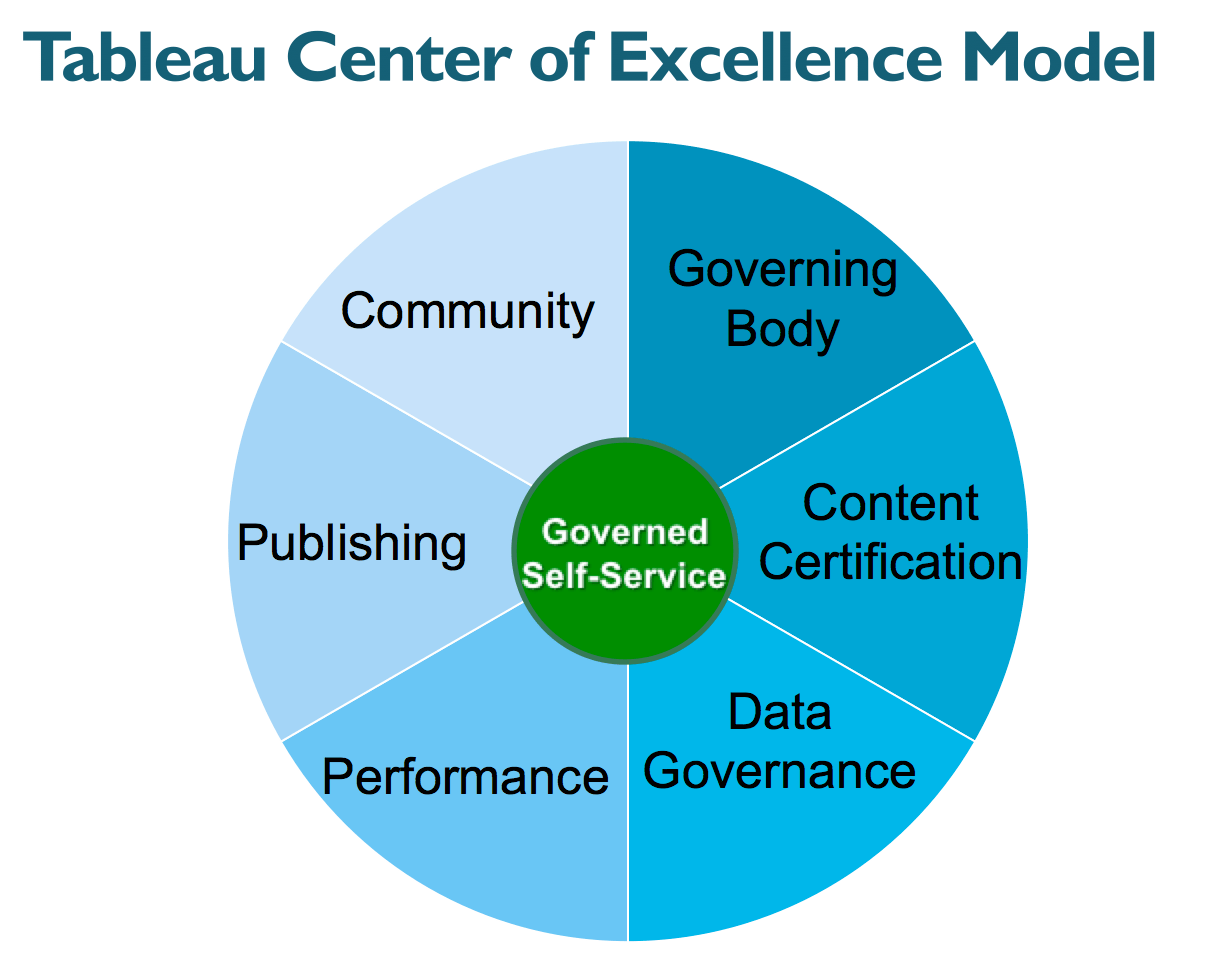
The publishing process & policy covers the followings areas: Engagement Process; Publisher Roles; Publishing Process and Dashboard Permissions.
 First step is to get a space on the shared enterprise self-service server for your group’s data and self-service dashboard, which is called Engagement Process. The main questions are:
First step is to get a space on the shared enterprise self-service server for your group’s data and self-service dashboard, which is called Engagement Process. The main questions are:
- From requester perspective, how to request a space on shared enterprise self-service server for my group
- From governance perspective, who decides and how to decide the self-service right fit?
Once a business group has a space on the shared enterprise self-service server, the business group has to ask the following questions:
- Who can publish dashboard from your group?
- Who oversees or manages all publishers in my group?
After you have given a publishing permission to some super users from your business group, those publishers need to know the rules, guidance, constraints on server, and best practices for effective dashboard publishing. Later on you may also want to make sure that your publishers are not creating the islands of information or creating multiple versions of KPIs.
- What are publishing rules?
- How to avoid duplications?
The purpose of publishing is to share your reports, dashboards, stories and insights to others who can make data-driven decisions. The audiences are normally defined already before you publishing the dashboards although dashboard permissions are assigned after publishing from workflow perspective. The questions are:
- Who can access the published dashboards?
- What is the approval process?
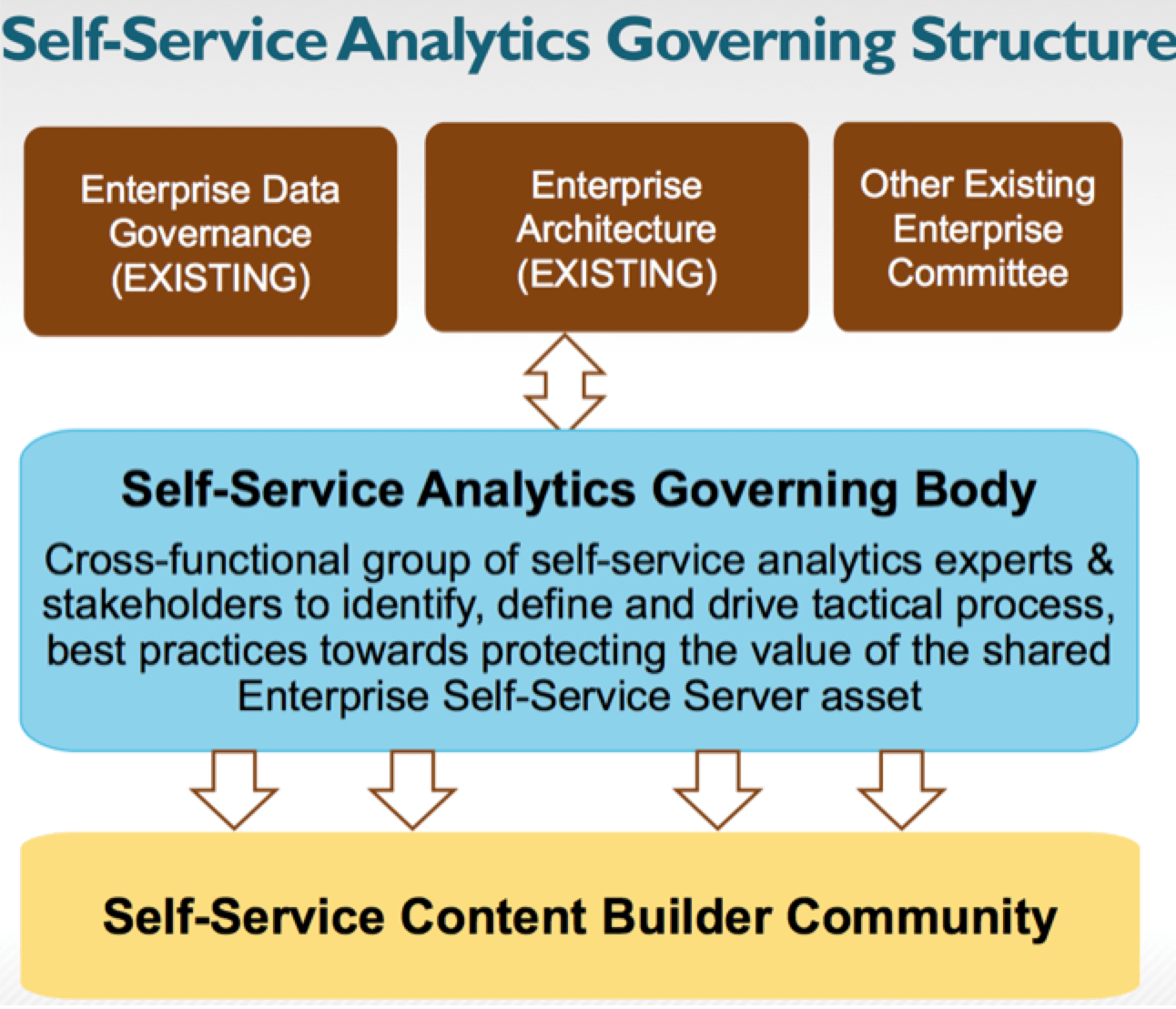
Engagement Process
Self-service analytics does not replace traditional BI tools but co-exists with traditional BI tools. It is very rare that you will find self-service analytics platform is the only reporting platform in your corporation. Very likely that you will have at least one IT-controlled enterprise-reporting platform designed for standard reporting to answer known questions using data populated from enterprise data warehouse. In additional to this traditional BI reporting platform, your organization has decided to implement a new self-service analytics platform to answer unknown questions and ad-hoc analysis using all the available data sources. 
This realization of traditional BI and self-service BI co-existing is important to understand this engagement process because guidance has to be defined which platform does what kinds of reporting. After this guidance is defined and agreed, continuous communication and education has to be done to make sure all self-service super users are in the same page for this strategic guidance.
Whenever there is a new request for a new self-service analytics application, fitness assessment has to be done before proceed. The following checklist serves this purpose:
- Does your bigger team have an existing site already on self-service analytics server? If yes, you can use the existing site.
- Who is the primary business / application contact?
- What business process / group does this application represent? (like sales, finance, etc)?
- Briefly describe the purpose and value of the application?
- Do you have an IT contact for your group for this application? Who is the contact?
- What are the data sources?
- Are there any sensitive data to be reporting on (like federal data, customer or client data)? If yes, describe in details about the source data.
- Are there any private data as part of source data? (like HR data, sensitive finance data)
- Who are the audiences of the reports? How many audiences do you anticipate? Are there any partners who will access the data?
- Does the source data have more than one enterprise data? If yes, what is the plan for data level security?
- What are the primary data elements / measures to be reporting on (e.g. booking, revenue, customer cases, expenses, etc)
- What will be the dimensions by which the measure will be shown (e.g. product, period, region, etc)
- How often the source data needs to be refreshed?
- What is anticipated volume of source data? How many quarters of data? Roughly how many rows of the data? Roughly how many columns of the data?
- Is the data available in enterprise data warehouse?
- How many self-service report developers for this application?
- Do you agree with organization’s Self-Service Analytics Server Governance policy (URL ….)?
- Do you agree with organization’s Self-Service Analytics Data Governance policy (URL ….)?
The above questionnaires also include your organization’s high-level policies on data governance, data privacy, service level agreement, etc since most of the existing self-service tools have some constraints in those areas. On one side, we want to encourage business teams to leverage the enterprise investment of the self-service analytics platform. On the other side, we want to make sure that every new application is setup for success and do not create chaos that can be very expensive to fix later on.
Publisher Roles
I heard a lot of exciting stories about how easy people can get new insights with visualization tools (like Tableau). Myself experienced a few of those insightful moments as well. However I also heard a story about new Tableau Desktop user who just came out of fundamental training, he quickly published something and shared to the team but caused a lot of confusions about the KPIs being published. What is wrong? It is not about the tool. It is not about the training but publishing roles and related process.
The questions are as followings:
- Who can publish dashboard from my group?
- Who oversees or manages all publishers in my group?
Sometimes you may have easy answers to those questions but you may not have easy answers for many other cases. One common approach is to use projects or folders to separate boundary for various publishers. Each project has project leader role who overalls all publishers within the project.
You can also define a common innovation zone where a lot of publishers can share their new insights to others. However just be aware that the dashboards in innovation zone are early discovery phase only and not officially agreed KPIs. Most of the dashboards will go through multiple iterations of feedback and improvement before become useful insights. We do encourage people to share their new innovations as soon as possible for feedback and improvement purpose. It will be better to distingue official KPIs with innovation by using different color templates to avoid the potential confusions to end audiences.
Publishing Process
To protect the shared self-service environment, you need to have clear defined publishing process:
- Does IT have to be involved before publish a dashboard to the server?
- Do you have to go from a non-production instance or non-production folder to a production folder?
- What is the performance guidance?
- Should you use live connection or extracts?
- How often you should schedule your extracts? Can you use full refresh?
- What are the data security requirements?
- Do you have some new business glossary in your dashboards? If yes, did you spell out the definition of the new business glossary?
- Does the new glossary definition need to get approval from data stewardship? Did you get the approval?
- Who supports the new dashboards?
- Does this new dashboard create potential duplication with existing ones?
Each organization or each business group will have different answers to those above questions. The answers to above questions form the basic publishing process that is essential for scalability and avoid chaos.
Here is summary of what most companies do – so call the common best practices:
- IT normally is not involved for the releasing or publishing process for those dashboards designed by business group – this is the concept of self-service
- IT and business agreed on the performance and extract guidance in advanced. IT will enforce some of the guidance on server policy settings (like extract timeout thresholds, etc). For many other parameters that can’t be systematically enforced, business and IT agreed on alert process to detect the exceptions. For example a performance alert that will be sent to dashboard owner and project owner (or site admin) if dashboard renders time exceeds 10 seconds.
- Business terms or glossary definition are important part of the dashboards.
- Business support process is defined so end information consumers know how to get help when they have questions about the dashboard or data.
- Dashboards are clarified as certified and non-certified. Non-certified dashboards are for feedback purpose while certified ones are officially approved and supported.
Dashboard Permissions
When you design a dashboard, most likely you have audiences defined already. The audiences have some business questions; your dashboards are to answer those questions. The audiences should be classified into groups and your dashboards can be assigned to one or multiple groups.
If your dashboards have row level security requirements, the complexity of dashboards will be increased many times. It is advised that business works with IT for the row level security design. Many self-service tools have limitations for row level security although they all claim row level security capability.
The best practice is to let database handle row level security to ensures data access consistence when you have multiple reporting tools against the same database. There are two challenges to figure out:
- Self-service visualization tool has to be able to pass session user variable dynamically to database. Tableau starts to support this feature for some database (like query banding feature for Teradata or initial SQL for Oracle)
- Database has user/group role tables implemented.
As summary, publishing involves a set of controls, process, policy and best practices. While support self-service and self-publishing, rules and processes have to be defined to avoid potential expensive mistakes later on.
Please read next blog for performance management








































































































 Starting V2018.3, Tableau officially supports new architecture configuration – a node has nothing but File Store (Hyper) and Data Engine (Data Engine has to be on every node). The
Starting V2018.3, Tableau officially supports new architecture configuration – a node has nothing but File Store (Hyper) and Data Engine (Data Engine has to be on every node). The
 The following will be the error msg for Desktop user connects to published data source on server when individual query limit reaches:
The following will be the error msg for Desktop user connects to published data source on server when individual query limit reaches: . Here is how it works:
. Here is how it works:












